My Machine Learning Learning Experience (Part 5): Decision theory - the Bayes decision rule and optimal risk
Note:
&space;=&space;\frac{P(X&space;|&space;Y&space;=&space;1)P(Y&space;=&space;1))}{P(X)} "P(Y = 1 | X) = \frac{P(X | Y = 1)P(Y = 1))}{P(X)}")
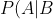&space;=&space;\frac{P(A&space;\cap&space;B)}{P(B)} "P(A|B) = \frac{P(A \cap B)}{P(B)}")
Likewise, the probability of event B given event A is:
&space;=&space;\frac{P(A&space;\cap&space;B)}{P(A)} "P(B|A) = \frac{P(A \cap B)}{P(A)}")
Rearrange and combine the above two equations and we obtain Bayes' Theorem:
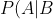&space;=&space;\frac{P(B|A)\cdot&space;P(A)}{P(B)} "P(A|B) = \frac{P(B|A)\cdot P(A)}{P(B)}")
Or we can also say

Why do we call them that?
Let's say we're tossing three coins with different probabilities of landing heads when tossed.
Let A, B and C be the event that the chosen coin was type A, type B, and type C. Let D be the event that the toss is heads. The problem now becomes finding P(A|D), P(B|D) and P(C|D).
Before, we dive into it, let's see what we now have first:
P(A) = 2/4 = 0.5
P(B) = 1/4 = 0.25
P(C) = 1/4 = 0.25
These are called Prior Probabilities because they are something "prior" before our observation. And what we are trying to find - P(A|D), P(B|D) and P(C|D), are the Posterior Probabilities, they are derived from or depend upon the specified value of D.
Look back at Bayes' Theorm, we have to calculate P(D|A), P(D|B) and P(D|C)
&space;=&space;\frac{P(data|model)\cdot&space;P(model)}{P(data)} "P(model|data) = \frac{P(data|model)\cdot P(model)}{P(data)}")
So basically, in machine learning, what we're trying to do here is we collect a bunch of data, we make a hypothesis based on the data and do predictions based on this hypothesis.
Let's illustrate all this using an example:
Suppose we have a population in which 10% has cancer, 90% doesn't, and the probability distributions for the people's calorie intake, P(X|Y) is:
Let's say we wanna find the probability that a person has a calorie intake between 1200 and 1600 cals:
&space;=&space;P(X|Y=1)P(Y=1)&space;+&space;P(X|Y=1)P(Y=-1)\\&space;\\&space;P(1200\leqslant&space;X&space;\leqslant&space;1600)&space;=&space;0.5&space;\cdot&space;0.1&space;+&space;0.1&space;\cdot&space;0.9&space;=&space;0.14 "\\Recall: P(X) = P(X|Y=1)P(Y=1) + P(X|Y=1)P(Y=-1)\\ \\ P(1200\leqslant X \leqslant 1600) = 0.5 \cdot 0.1 + 0.1 \cdot 0.9 = 0.14")
This time, a dude who eats 1400 cals a day comes to us and asks us if he has cancer. Let's see.
Using Bayes' Theorem, the posterior probability
So for 1200 <= X <= 1600,
&space;=&space;\frac{0.5&space;\cdot&space;0.1}{0.14}&space;=&space;\frac{5}{14}\\&space;\\&space;P(Y=-1&space;|&space;X)&space;=&space;\frac{0.1&space;\cdot&space;0.9}{0.14}&space;=&space;\frac{9}{14} "P(Y=1 | X) = \frac{0.5 \cdot 0.1}{0.14} = \frac{5}{14}\\ \\ P(Y=-1 | X) = \frac{0.1 \cdot 0.9}{0.14} = \frac{9}{14}")
Therefore, P(cancer | X = 1400 cals) - P(Y = 1 | X) = 5 /14 = 36%.
So this guy is unlikely to have cancer. Note that the sum of the two probabilities equal one.
In short, what we're trying to do now is calculate everything using the data we have and then comparing P(Y = 1 | X) and P(Y = 1 | X) and do predictions. Our target is the posterior P(Y = 1 | X). Keep this in mind.
&space;=&space;\left\{\begin{matrix}&space;1&space;&&space;for\quad&space;incorrect\quad&space;predictions\\&space;0&space;&&space;for\quad&space;correct\quad&space;predictions&space;\end{matrix}\right. "L(z, y) = \left\{\begin{matrix} 1 & for\quad incorrect\quad predictions\\ 0 & for\quad correct\quad predictions \end{matrix}\right.")
where z stands for the predicted value, y represents the true value. This is called the 0-1 loss function.
However, sometimes a 0-1 loss function is not enough, because we don't wanna just give a correct prediction. Using the cancer example, we'd want our test to give more false positives than false negatives. Why? You asked. Because a false negative might mean that somebody who has cancer doesn't catch their cancer until years later it's advanced and the opportunity to save their lives has been lost. On the other hand, the only cost of a false positive is more expensive test to check if you really have cancer. In short, we want more false positives than false negatives. In order to do that, we can design a loss function like this:
&space;=&space;\left\{\begin{matrix}&space;1&space;&&space;if\quad&space;z&space;=&space;1,&space;y&space;=&space;-1,\quad&space;i.e.\quad&space;false\quad&space;positive\quad&space;is\quad&space;bad&space;\\&space;5&space;&&space;if\quad&space;z&space;=&space;-1,&space;y&space;=&space;+1,\quad&space;i.e.\quad&space;false\quad&space;negative\quad&space;is\quad&space;really\quad&space;bad\\&space;0&space;&&space;if&space;z&space;=&space;y&space;\end{matrix}\right. "L(z,y) = \left\{\begin{matrix} 1 & if\quad z = 1, y = -1,\quad i.e.\quad false\quad positive\quad is\quad bad \\ 5 & if\quad z = -1, y = +1,\quad i.e.\quad false\quad negative\quad is\quad really\quad bad\\ 0 & if z = y \end{matrix}\right.")
which is asymmetrical, because false positives and false negatives are not penalized equally.

So r is a function that maps a feature vector x to 1 ("in class") or -1 ("not in class").
Risk is the expected loss, that is, how much loss we are going to get if we use this decision rule. And of course, we will want this risk as small as possible. And to calculate the Risk, Expected Loss R(r) over all values of x and y:
&space;&=&space;E[L(r(X),Y)]&space;\\&space;&=&space;\sum_{x,y}&space;L(r(X),Y)&space;\cdot&space;P(X,Y)\\&space;&=&space;\sum_{x}&space;(L(r(X),&space;1)&space;\cdot&space;P(Y&space;=&space;1&space;|&space;X&space;=&space;x)&space;+&space;L(r(X),&space;-1)&space;\cdot&space;P(Y&space;=&space;-1&space;|&space;X&space;=&space;x))P(X)\\&space;&=&space;\sum_{x}&space;L(r(X),&space;1)P(X&space;=&space;x|&space;Y&space;=&space;1)P(Y&space;=&space;1)&space;+&space;\sum_{x}&space;L(r(X),&space;-1)P(X&space;=&space;x&space;|&space;Y&space;=&space;-1)P(Y&space;=&space;-1)&space;\\&space;&=&space;P(Y&space;=&space;1)\sum_{x}&space;L(r(X),&space;1)P(X&space;=&space;x|&space;Y&space;=&space;1)&space;+&space;P(Y&space;=&space;-1)\sum_{x}&space;L(r(X),&space;-1)P(X&space;=&space;x&space;|&space;Y&space;=&space;-1)&space;\end{align*} "\begin{align*} R(r) &= E[L(r(X),Y)] \\ &= \sum_{x,y} L(r(X),Y) \cdot P(X,Y)\\ &= \sum_{x} (L(r(X), 1) \cdot P(Y = 1 | X = x) + L(r(X), -1) \cdot P(Y = -1 | X = x))P(X)\\ &= \sum_{x} L(r(X), 1)P(X = x| Y = 1)P(Y = 1) + \sum_{x} L(r(X), -1)P(X = x | Y = -1)P(Y = -1) \\ &= P(Y = 1)\sum_{x} L(r(X), 1)P(X = x| Y = 1) + P(Y = -1)\sum_{x} L(r(X), -1)P(X = x | Y = -1) \end{align*}")
&space;=&space;\left\{\begin{matrix}&space;1&space;&&space;if\quad&space;L(-1,1)P(Y=1|X=x)&space;>&space;L(1,-1)P(Y=-1|X=x)\\&space;-1&space;&&space;otherwise&space;\end{matrix}\right. "r^{*}(x) = \left\{\begin{matrix} 1 & if\quad L(-1,1)P(Y=1|X=x) > L(1,-1)P(Y=-1|X=x)\\ -1 & otherwise \end{matrix}\right.")
I actually don't quite understand what this part is doing, so if anyone can show me what's going on it'd be great. In the meantime, I understand it like this:
Previously, we compare the two probabilities P(Y = 1 | X = x) and P(Y = -1 | X = x) and choose the larger one to determine if Y = 1 or -1, which makes total sense. However, since there's a chance that we'll screw up and make the wrong prediction. Considering this possibility, we take 'loss' into the mix and compare the risks instead. But how? I thought about the following stuff myself, so it could be wrong, don't say I didn't warn you.
Still considering two-class classification, we only have two actions:

And I'm calculating their risk (i.e. expected loss) given x accordingly:
}&space;&=&space;E[L(r(x),&space;Y)]\\&space;&=&space;\sum_{y}&space;L(r(x),&space;Y)&space;\cdot&space;P(X&space;=&space;x,Y)\\&space;&=&space;\sum_{y&space;=&space;1,-1}&space;L(1,&space;Y)&space;\cdot&space;P(X&space;=&space;x,Y)\\&space;&=&space;L(1,&space;1)&space;\cdot&space;P(X&space;=&space;x,&space;Y&space;=&space;1)&space;+&space;L(1,&space;-1)&space;\cdot&space;P(X&space;=&space;x,&space;Y&space;=&space;-1)\\&space;&=&space;\mathbf{L(1,&space;-1)&space;\cdot&space;P(X&space;=&space;x,Y&space;=&space;-1)}&space;\quad(Assuming\quad&space;L(z,y)&space;=&space;0\quad&space;for\quad&space;z&space;=&space;y)&space;\end{align*} "\begin{align*} \mathbf{R(\alpha_1 | x)} &= E[L(r(x), Y)]\\ &= \sum_{y} L(r(x), Y) \cdot P(X = x,Y)\\ &= \sum_{y = 1,-1} L(1, Y) \cdot P(X = x,Y)\\ &= L(1, 1) \cdot P(X = x, Y = 1) + L(1, -1) \cdot P(X = x, Y = -1)\\ &= \mathbf{L(1, -1) \cdot P(X = x,Y = -1)} \quad(Assuming\quad L(z,y) = 0\quad for\quad z = y) \end{align*}")
}&space;&=&space;E[L(r(x),&space;Y)]\\&space;&=&space;\sum_{y}&space;L(r(x),&space;Y)&space;\cdot&space;P(X&space;=&space;x,Y)\\&space;&=&space;\sum_{y&space;=&space;1,-1}&space;L(-1,&space;Y)&space;\cdot&space;P(X&space;=&space;x,Y)\\&space;&=&space;L(-1,&space;1)&space;\cdot&space;P(X&space;=&space;x,&space;Y&space;=&space;1)&space;+&space;L(-1,&space;-1)&space;\cdot&space;P(X&space;=&space;x,&space;Y&space;=&space;-1)\\&space;&=&space;\mathbf{L(-1,&space;1)&space;\cdot&space;P(X&space;=&space;x,Y&space;=&space;1)}&space;\quad(Assuming\quad&space;L(z,y)&space;=&space;0\quad&space;for\quad&space;z&space;=&space;y)&space;\end{align*} "\begin{align*} \mathbf{R(\alpha_{-1} | x)} &= E[L(r(x), Y)]\\ &= \sum_{y} L(r(x), Y) \cdot P(X = x,Y)\\ &= \sum_{y = 1,-1} L(-1, Y) \cdot P(X = x,Y)\\ &= L(-1, 1) \cdot P(X = x, Y = 1) + L(-1, -1) \cdot P(X = x, Y = -1)\\ &= \mathbf{L(-1, 1) \cdot P(X = x,Y = 1)} \quad(Assuming\quad L(z,y) = 0\quad for\quad z = y) \end{align*}")
If what we care about is if we should assign Y = 1 or not, we want the risk of action 1 to be less than action -1, i.e.
}&space;&<&space;\mathbf{R(\alpha_{-1}&space;|&space;x)}\\&space;L(1,&space;-1)&space;\cdot&space;P(X&space;=&space;x,Y&space;=&space;-1)&space;&<&space;L(-1,&space;1)&space;\cdot&space;P(X&space;=&space;x,Y&space;=&space;1)\\&space;L(-1,&space;1)&space;\cdot&space;P(X&space;=&space;x,Y&space;=&space;1)&space;&>&space;L(1,&space;-1)&space;\cdot&space;P(X&space;=&space;x,Y&space;=&space;-1)&space;\end{align*} "\begin{align*} \mathbf{R(\alpha_1 | x)} &< \mathbf{R(\alpha_{-1} | x)}\\ L(1, -1) \cdot P(X = x,Y = -1) &< L(-1, 1) \cdot P(X = x,Y = 1)\\ L(-1, 1) \cdot P(X = x,Y = 1) &> L(1, -1) \cdot P(X = x,Y = -1) \end{align*}")
And so, we have the same result as above:
&space;=&space;\left\{\begin{matrix}&space;1&space;&&space;if\quad&space;L(-1,1)P(Y=1|X=x)&space;%3E&space;L(1,-1)P(Y=-1|X=x)\\&space;-1&space;&&space;otherwise&space;\end{matrix}\right. "r^{*}(x) = \left\{\begin{matrix} 1 & if\quad L(-1,1)P(Y=1|X=x) > L(1,-1)P(Y=-1|X=x)\\ -1 & otherwise \end{matrix}\right.")
&space;&=&space;P(Y=1)(L(-1,1)P(X>1600|Y=1))&space;+&space;P(Y=-1)L(1,-1)(P(X<1200&space;|&space;Y&space;=&space;-1)+P(1200<X<1600|Y=-1))&space;\\&space;&=&space;(0.1&space;\cdot&space;5&space;\cdot&space;0.3)&space;+&space;(0.9&space;\cdot&space;1&space;\cdot&space;(0.01&space;+&space;0.1))&space;\\&space;&=&space;0.249&space;\end{align*} "\begin{align*} R(r^*) &= P(Y=1)(L(-1,1)P(X>1600|Y=1)) + P(Y=-1)L(1,-1)(P(X<1200 | Y = -1)+P(1200<X<1600|Y=-1)) \\ &= (0.1 \cdot 5 \cdot 0.3) + (0.9 \cdot 1 \cdot (0.01 + 0.1)) \\ &= 0.249 \end{align*}")

=\frac{P(X|Y)P(Y)}{P(X)} "P(Y|X)=\frac{P(X|Y)P(Y)}{P(X)}")

&space;&=&space;E[L(r(x),&space;Y)]&space;\\&space;&=&space;P(Y=1)&space;\int&space;L(r(x),1)P(X=x|Y=1)dx&space;+&space;P(Y=-1)&space;\int&space;L(r(x),-1)P(X=x|Y=-1)dx&space;\end{align*} "\begin{align*} R(r) &= E[L(r(x), Y)] \\ &= P(Y=1) \int L(r(x),1)P(X=x|Y=1)dx + P(Y=-1) \int L(r(x),-1)P(X=x|Y=-1)dx \end{align*}")
&space;=&space;\int&space;\underset{y=\pm&space;1}{min}&space;\quad&space;L(-y,&space;y)&space;P(X=x&space;|&space;Y&space;=y)&space;P(Y=y)dx&space;\end{align*} "\begin{align*} R(r^*) = \int \underset{y=\pm 1}{min} \quad L(-y, y) P(X=x | Y =y) P(Y=y)dx \end{align*}")
- This is the first of a series of the notes that I made when I was struggling though my machine learning journey.
- A lot of the stuff I'm ripping off CS189, a machine learning course from Stanford University, namely in Spring 2016. The professor, Jonathan Shewchuk, did a really good job on going through everything. I'm still confused by some of the mathematical stuff though, but after checking out numerous lecture videos from college professors that are made available online, this guy is the best I can get.
- So yeah, I was watching three series of lecture videos, two from Udacity and one from Stanford.
- I colored stuff that you can skip, blue. When I say you can skip, that doesn't mean those parts are not important, because usually they are examples and detailed explanation which are extremely helpful for understanding what's going on. But if you've already had a basic understanding of everything and just wanna get a quick review, just skip them.
- For every section, I always picture we have a target to achieve, because we have to! Otherwise, what's the point of going through all these models and maths and assumptions and statistics? And going through all these also tend to spin our heads around and makes us forget what we're here for. Therefore, I colored them red so we can always keep the objective in our mind.
- And finally, I also wrote some stuff that are colored fuchsia(or call it purple, pink, I don't care), these are the background information for what we're talking about there.
Bayes' Theorem
I'm gonna start with stating Bayes' Theorem:Review:
Recall the definition of Conditional Probability, the probability of event A given event B is:Likewise, the probability of event B given event A is:
Rearrange and combine the above two equations and we obtain Bayes' Theorem:
Or we can also say
Why do we call them that?
Let's say we're tossing three coins with different probabilities of landing heads when tossed.
- Type A coins are fair, with probability .5 of heads
- Type B coins are bent and have probability .6 of heads
- Type C coins are bent and have probability .9 of heads
- 2 of type A,
- 1 of type B,
- 1 of type C.
Let A, B and C be the event that the chosen coin was type A, type B, and type C. Let D be the event that the toss is heads. The problem now becomes finding P(A|D), P(B|D) and P(C|D).
Before, we dive into it, let's see what we now have first:
P(A) = 2/4 = 0.5
P(B) = 1/4 = 0.25
P(C) = 1/4 = 0.25
These are called Prior Probabilities because they are something "prior" before our observation. And what we are trying to find - P(A|D), P(B|D) and P(C|D), are the Posterior Probabilities, they are derived from or depend upon the specified value of D.
Look back at Bayes' Theorm, we have to calculate P(D|A), P(D|B) and P(D|C)
- P(D|A) = 0.5
- P(D|B) = 0.6
- P(D|C) = 0.9
These probabilities mean the probabilities of the data assuming that the hypothesis is true (for instance, P(D|A) is the probability of the coin gives a head if the coin is Type A), thus are called Likelihood.
And now, we can actually calculate the posteriors*:
- P(A|D) = P(D|A)P(A) = 0.5 * 0.5 = 0.25
- P(B|D) = P(D|B)P(B) = 0.6 * 0.25 = 0.15
- P(C|D) = P(D|C)P(C) = 0.9 * 0.25 = 0.225
So we can tell it's very much like a Type A coin we picked from the drawer. Oh wait, don't we still have to calculate P(D) in order to calculate the posteriors. Okay, so
- P(D) = P(A)P(D|A) + P(B)P(D|B) + P(C)P(D|C) = 0.625
As you can see I'm just adding all the posteriors* together. And therefore, the posteriors are actually:
- P(A|D) = 0.25 / 0.625 = 0.4
- P(B|D) = 0.15 / 0.625 = 0.24
- P(C|D) = 0.225 / 0.625 = 0.36
And based on this we can still draw the same conclusion. How we do this is we only care about how likely the coin is Type A or whatever it can be by comparison. So we actually don't care as much about P(D), which you now understand why we also call it Normalising Constant.
After reviewing Bayes' Theorem, there's one more thing to note, instead of only writing a bunch of X and Y, we usually apply Bayes' Theorem like this:
Let's illustrate all this using an example:
Suppose we have a population in which 10% has cancer, 90% doesn't, and the probability distributions for the people's calorie intake, P(X|Y) is:
| calories(X) | <1200 | 1200-1600 | >1600 |
|---|---|---|---|
| cancer(Y=1) | 20% | 50% | 30% |
| no cancer(Y=-1) | 1% | 10% | 89% |
Let's say we wanna find the probability that a person has a calorie intake between 1200 and 1600 cals:
This time, a dude who eats 1400 cals a day comes to us and asks us if he has cancer. Let's see.
Using Bayes' Theorem, the posterior probability
So for 1200 <= X <= 1600,
Therefore, P(cancer | X = 1400 cals) - P(Y = 1 | X) = 5 /14 = 36%.
So this guy is unlikely to have cancer. Note that the sum of the two probabilities equal one.
In short, what we're trying to do now is calculate everything using the data we have and then comparing P(Y = 1 | X) and P(Y = 1 | X) and do predictions. Our target is the posterior P(Y = 1 | X). Keep this in mind.
Loss Function
So for every prediction we make based on the equation we wanna calculate the loss, so we can know how much we are screwed when we make a wrong prediction, that is, L(z,y) specifies badness if true class is y, classifier prediction is z. So we define the following Loss Function, for instance:where z stands for the predicted value, y represents the true value. This is called the 0-1 loss function.
However, sometimes a 0-1 loss function is not enough, because we don't wanna just give a correct prediction. Using the cancer example, we'd want our test to give more false positives than false negatives. Why? You asked. Because a false negative might mean that somebody who has cancer doesn't catch their cancer until years later it's advanced and the opportunity to save their lives has been lost. On the other hand, the only cost of a false positive is more expensive test to check if you really have cancer. In short, we want more false positives than false negatives. In order to do that, we can design a loss function like this:
which is asymmetrical, because false positives and false negatives are not penalized equally.
Decision Rule and Risk
So r is a function that maps a feature vector x to 1 ("in class") or -1 ("not in class").
Risk is the expected loss, that is, how much loss we are going to get if we use this decision rule. And of course, we will want this risk as small as possible. And to calculate the Risk, Expected Loss R(r) over all values of x and y:
Bayesian Decision Rule
And by choosing a r that minimizes R(r), we have the Bayesian Decision Rule (aka Bayes Classifier) r*. So assuming L(z,y) = 0 for z = y:I actually don't quite understand what this part is doing, so if anyone can show me what's going on it'd be great. In the meantime, I understand it like this:
Previously, we compare the two probabilities P(Y = 1 | X = x) and P(Y = -1 | X = x) and choose the larger one to determine if Y = 1 or -1, which makes total sense. However, since there's a chance that we'll screw up and make the wrong prediction. Considering this possibility, we take 'loss' into the mix and compare the risks instead. But how? I thought about the following stuff myself, so it could be wrong, don't say I didn't warn you.
Still considering two-class classification, we only have two actions:
And I'm calculating their risk (i.e. expected loss) given x accordingly:
If what we care about is if we should assign Y = 1 or not, we want the risk of action 1 to be less than action -1, i.e.
And so, we have the same result as above:
Going back to our cancer example,
r* = 1 if intakes <= 1600; r* = -1 for calories intakes > 1600
And the Bayesian Risk, aka optimal risk will be
Continuous Case
Now suppose our cancer statistics looks like this:
The red curve is the calories intake of patients
The blue curve is the calories intake of people who don't have cancers

To be more clear, you can view the x-axis as the calories intake and the y-axis as the number of people. This is the data we usually have in the real world, and our goal, of course, is to find the posterior P(Y|X).
To the make case even simpler, we're gonna use 0-1 loss function. That is, if we have a false positive, the loss is 1. If we have a false negative, the loss is also 1.
Suppose P(Y=1) = 1/3. P(Y=2) = 2/3. Where do these numbers usually come from? Let's say we interviewed 1200 people, 400 of them have cancers, and the remaining 800 do not, then P(Y=1) = 400/(400 + 800) = 1/3. P(Y=-1) is calculated in the same way.
Recall Bayes' Theorem
And now we have P(X|Y=1), P(Y=1), P(X|Y=-1) and P(Y=-1). That means we have the numerators of P(Y=1|X) and P(Y=-1|X) by multiplying them together. With this, we can modify the curve to this:

The intersection point is where these two curves meet and the dividing point where on the right part are the people who don't have cancers and the people who have cancers are on the left. The vertical line is the Bayes Optimal Decision Boundary.
Define risk as before, replace summations with integrals:
If L is 0-1 loss, R(r) = P(r(x) is wrong)
For Bayes decision rule, Bayes risk is the area under the minimum of the functions above, i.e. the shaded area.
Assuming L(z,y) = 0 for z = y,
Kev
My Machine Learning Learning Experience (Part 5): Decision theory - the Bayes decision rule and optimal risk
 Reviewed by Kevin Lai
on
10:32:00 PM
Rating:
Reviewed by Kevin Lai
on
10:32:00 PM
Rating:
Reviewed by Kevin Lai
on
10:32:00 PM
Rating:




Great insights on decision theory, the Bayes decision rule, and optimal risk in machine learning! For reliable hosting services, check out atmosphereswitch.
ReplyDelete